Socket.IO is a JavaScript library for realtime web applications. It comes in two parts - a client-side library that runs in the browser and a server-side library for Node.js. In this post I will walk you through complete integration scenario with Oracle JET.
Here you can see it in action. Send Event button from JET - sends message through Socket.IO to Node.js server side. Message is handled on server side and response is sent back to client (displayed in browser console):

Server side part with Socket.io is implemented in Node.js application and it runs on Express. To create Node.js application (which is just one json file in the beginning), run command:
npm init
To add Express and Socket.io, run commands:
npm install express --save
npm install socket.io --save
To start Node.js application on Express, run command:
npm start
Double check package.json, it should contain references to Express and Socket.IO:

Here is server side code for Socket.IO (I created server.js file manually). When connection is established with the client, message is printed. Method socket.on listens for incoming messages. Method socket.emit transmits message to client. In both cases we can use JSON structure for payload variable. There is cheatsheet for socket.emit - Socket.IO - Emit cheatsheet. Socket.IO server side:

Socket.IO client side can be installed into JET application with NPM. There is separate section in Oracle JET documentation, where you can read step by step instructions about 3-rd party library installation into Oracle JET - Adding Third-Party Tools or Libraries to Your Oracle JET Application. I would recommend manually include Socket.IO dependency entry into package.json in JET:

Then run command to fetch Socket.IO library into JET application node modules. Next continue with instructions from Oracle JET guide and check my sample code:
npm update
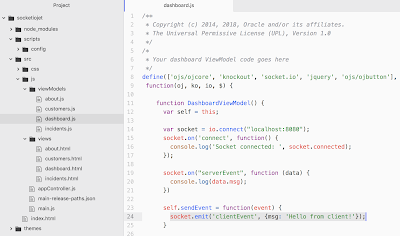
To establish socket connection - import Socket.IO into JET module and use io.connect to establish socket connection. Connect to the end point where Express is running with server side Socket.IO listener. Client side is using same socket.on and socket.emit API methods as server side:
Download sample code from my GitHub repository.
Here you can see it in action. Send Event button from JET - sends message through Socket.IO to Node.js server side. Message is handled on server side and response is sent back to client (displayed in browser console):

Server side part with Socket.io is implemented in Node.js application and it runs on Express. To create Node.js application (which is just one json file in the beginning), run command:
npm init
To add Express and Socket.io, run commands:
npm install express --save
npm install socket.io --save
To start Node.js application on Express, run command:
npm start
Double check package.json, it should contain references to Express and Socket.IO:

Here is server side code for Socket.IO (I created server.js file manually). When connection is established with the client, message is printed. Method socket.on listens for incoming messages. Method socket.emit transmits message to client. In both cases we can use JSON structure for payload variable. There is cheatsheet for socket.emit - Socket.IO - Emit cheatsheet. Socket.IO server side:

Socket.IO client side can be installed into JET application with NPM. There is separate section in Oracle JET documentation, where you can read step by step instructions about 3-rd party library installation into Oracle JET - Adding Third-Party Tools or Libraries to Your Oracle JET Application. I would recommend manually include Socket.IO dependency entry into package.json in JET:

Then run command to fetch Socket.IO library into JET application node modules. Next continue with instructions from Oracle JET guide and check my sample code:
npm update
To establish socket connection - import Socket.IO into JET module and use io.connect to establish socket connection. Connect to the end point where Express is running with server side Socket.IO listener. Client side is using same socket.on and socket.emit API methods as server side:

Download sample code from my GitHub repository.