JET 6.0.0 officially supports TypeScript, wow that great news. If you are building large JavaScript application with JET, it will be much easier to manage code with TypeScript - it does type checking and reports code errors during build time. Logic can be encapsulated into classes with inheritance. Read more about classes support in TypeScript.
In this post I will share simple JET application enabled with TypeScript support. Sample application can be downloaded from GitHub repo. Before running it with ojet serve, make sure to execute ojet restore to install all dependent modules.
If you want to add TypeScript support to the new JET app, this can be achieved with npm command, executed in application root:
npm install @types/oracle__oraclejet
I would recommend to use Microsoft Visual Studio Code for Oracle JET development with TypeScript. IDE comes with very good support for TypeScript, it supports autocompletion, debugging - I'm sure it will make JET development faster.
To be able to use TypeScript, install it globally with this command (read more about various options - TypeScript setup):
npm install -g typescript
First step is to add tsconfig.json to the root folder of JET app. This configuration file enables TypeScript support in JET app. You can copy tsconfig.json from JET in TypeScript guide. I have updated outDir to my app folder structure, this allows to write translated JS file out of TypeScript directly into standard JET folder with JS files and override JS module:

Next we should create new TypeScript file (extension ts) under typescripts folder. File name should match existing JS module file name, in order for that JS target file to be overridden during TypeScript build:

TypeScript reports code errors during build time - for example, function name not found:

Visual Code provides auto completion for JET code, for example it helps to import module:

In TypeScript we can define classes. Variables can be created as objects of certain class, this helps to define input parameter types and do strict type checks when passing these variables into functions. Study this simple code example written in TypeScript, take a look how observable variable is defined:

Visual Code offers build command to translate TypeScript code into JS:

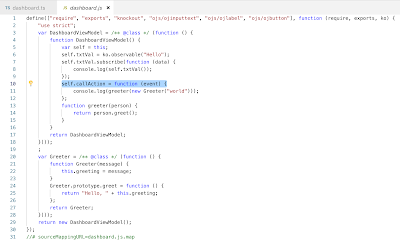
Once build completes, we get translated JS code associated with JET module. Take a look how class was translated. See how callAction function was translated with event input parameter:
HTML part of JET module remains same as without TypeScript:

Observable variable change is handled in TypeScript:

Action listener is invoked and function with class type parameter is called:

In this post I will share simple JET application enabled with TypeScript support. Sample application can be downloaded from GitHub repo. Before running it with ojet serve, make sure to execute ojet restore to install all dependent modules.
If you want to add TypeScript support to the new JET app, this can be achieved with npm command, executed in application root:
npm install @types/oracle__oraclejet
I would recommend to use Microsoft Visual Studio Code for Oracle JET development with TypeScript. IDE comes with very good support for TypeScript, it supports autocompletion, debugging - I'm sure it will make JET development faster.
To be able to use TypeScript, install it globally with this command (read more about various options - TypeScript setup):
npm install -g typescript
First step is to add tsconfig.json to the root folder of JET app. This configuration file enables TypeScript support in JET app. You can copy tsconfig.json from JET in TypeScript guide. I have updated outDir to my app folder structure, this allows to write translated JS file out of TypeScript directly into standard JET folder with JS files and override JS module:

Next we should create new TypeScript file (extension ts) under typescripts folder. File name should match existing JS module file name, in order for that JS target file to be overridden during TypeScript build:

TypeScript reports code errors during build time - for example, function name not found:

Visual Code provides auto completion for JET code, for example it helps to import module:

In TypeScript we can define classes. Variables can be created as objects of certain class, this helps to define input parameter types and do strict type checks when passing these variables into functions. Study this simple code example written in TypeScript, take a look how observable variable is defined:

Visual Code offers build command to translate TypeScript code into JS:

Once build completes, we get translated JS code associated with JET module. Take a look how class was translated. See how callAction function was translated with event input parameter:

HTML part of JET module remains same as without TypeScript:

Observable variable change is handled in TypeScript:

Action listener is invoked and function with class type parameter is called:































