When we are talking with customers about Oracle ADF performance, very often we can hear such question - "Hey, ADF works well when there are few concurrent users, how it behaves when there is more serious load?". In order to answer this question I will publish series of posts, where we will study different parameters for AM pool tuning and test AM pool configuration under stress loads. Today we will see how stable is AM pool passivation/activation mechanism.
Stress tests are implemented with JMeter. Check Chris Muir
blog about JMeter configuration for ADF 11g. I'm using JMeter configuration file from Chris blog, however original file is updated with internal loops to repeat session requests. JMeter allows to run stress test with multiple parallel users, each users starts its own HTTP session. It is not enough for stress test, additionally I would like to repeat user action within the same HTTP session - its why internal loops are needed, these loops allow to iterate through the same requests multiple times.
We will run 3 test scenarios (hardware: 4 virtual processors, 4 GB RAM):
1. Optimistic (15 concurrent users, 300 transactions in 10 minutes)
2. Average (25 concurrent users, 5000 transactions in 10 minutes)
3. Pessimistic (80 concurrent users, 16000 transactions in 10 minutes)
Each scenario consists of these steps:
1. Session initialization
2. Open Departments page (local AM)
3. Perform data change and Commit operation. Repeat 100 times per user, with 3 seconds wait time
4. Open Employees page (region imported from ADF library)
5. Perform data change and Commit operation. Repeat 100 times per user, with 3 seconds wait time
Wait time in the loop - 3 seconds:
Download sample application for stress test -
stresstest_v1.zip. Sample contains two applications - main and application library. Both applications implement two AM modules, pool settings for both AM's are configured to the same values. There are two pages inside main application, first page brings data from local AM, second from imported region and related AM:
Second page integrates ADF region from ADF library:
Stress test is designed to run such scenarion, where user clicks on Submit button from ADF UI, this button calls custom method from AM interface. Custom AM method is accessing VO row, by randomized value in range based on VO rowset size. Numeric attribute value is changed (incremented by 1) for every accessed row, transaction is committed or reverted back, depending on concurrent modification. Additionally we have one transient attribute, it is set to be passivated:
All 3 stress test scenarios (Optimistic, Average and Pessimistic) are executed with the same AM pool configuration (for both AM's) - based on rough estimate of approximately 20 concurrent users in the system:
- Initial Pool Size = 22 (number of AM instances created on first ever access, recommended to be 10% more than estimated number of concurrent users)
- Maximum Pool Size = 30 (number of maximum AM instances pool can create, recommended to be 20%-30% more than initial pool size)
- Referenced Pool Size = 20 (number of active AM instances, recommended to be the same as estimated number of concurrent users - to avoid frequent passivation/activation)
- Minimum Available Size = 0 (when set to 0, allows to release all AM instances after idle timeout, this helps to release reserved database connections as well. Is set to 0 for tests in stress environment, in your system you may set it to higher value, but less than referenced pool size)
- Maximum Available Size = 25 (maximum number of AM instances after pool clean-up)
- Idle Instance Timeout = 300 (AM instance is considered inactive after 5 minutes of inactivity, this if for stress test. In your system you would set it something close to Web session timeout - to prevent frequent passivation/activation)
- Pool Pooling Interval = 120 (AM pool is cleaned every 2 minutes)
1. Optimistic (15 concurrent users, 300 transactions in 10 minutes)
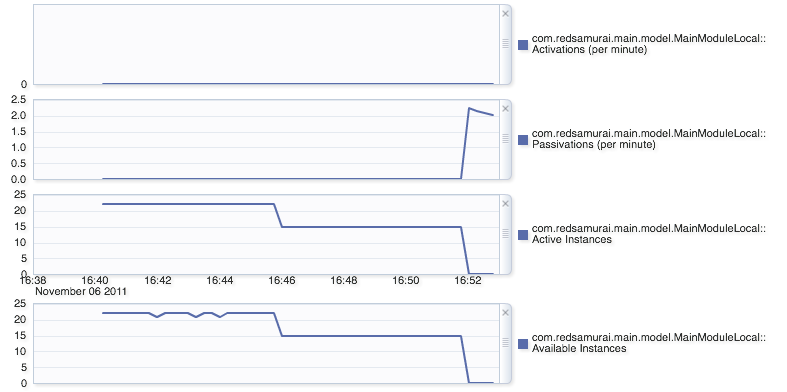
This test is performed on first ever access. As you can see, 22 AM instances are created, as per initial pool size setting. However, soon (idle time 5 mins + pool cleaning interval 2 mins) 7 AM instances are removed - because we have only 15 online users. Passivation/activation never happens (because referenced pool is set to be for 20, and we have only 15). MainModule statistics:
Same for HrModule module:
Very important, because Minimum Available Size = 0, after idle time entire pool is cleaned:
Same with DB connections, there is no need to wait for AM time to live, AM instances and DB connections can be released earlier - however this will trigger passivation. DB connection can be released before AM time to live, by tuning AM pool Minimum Available Size and AM Instance Timeout:
2. Average (25 concurrent users, 5000 transactions in 10 minutes)
This test with 25 online users is slightly above Referenced Pool Size = 20. We should experience passivation/activation behavior.
AM pool allocates 20 active instances for 25 users (as per Referenced Pool Size). Passivation/activation starts to take place, in order to support all 25 users (around 500 passivation/activation circles per minute):
Similar behavior for the second AM:
40 DB connections are used during peak time, when both AM's are active (20 + 20 active AM instances):
As you can see, even Maximum Pool Size = 30, active instance size is not exceeding Referenced Pool Size.
3. Pessimistic (80 concurrent users, 16000 transactions in 10 minutes)
With 80 users, AM pool starts to passivate/activate much more (as expected). There are 20 active AM's, as per Referenced Pool Size and those 20 AM's need to serve all 80 users. There are lots of switch activity happening - around 1500 passivation/activation circles in 1 minute:
Runtime statistics for the second AM:
During strong stress test, we can see that we were using at some moments more than 40 (20 per each AM) database connections (as previous test). Means AM pool during heavy stress test may maintain more active AM instances than specified by Referenced Pool Size - but still, AM size will not exceed Maximum Pool Size setting (30 in our case):
Conclusion: AM Pool is strong enough to handle stress peaks with online users greatly exceeding number of AM Pool Size and and AM Referenced Pool Size. However, in your system you should try to maintain AM Pool sizing as close as possible to expected number of online users - this will help to avoid performance costly passivation/activation operations.